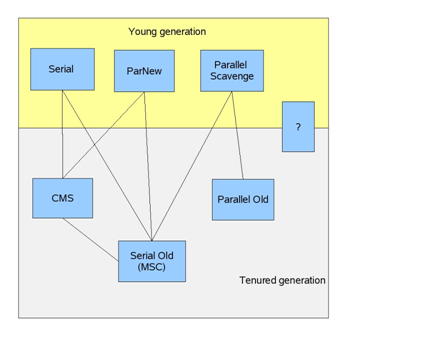
|
Parallel Scavenge:
和Serial相比,它的特点在于使用multi-thread来处理GC,当然,在执行的时候,仍然会“stop-the-world”,好处在于,暂停的时间也许更短;
 ParNew:
它基本上和Parallel Scavenge非常相似,唯一的区别,在于它做了强化能够和CMS一起使用;
负责Tenured Generation的collector也有三种:
Serial Old:
单线程,采用的是mark-sweep-compact回收方法(好吧,我承认我不知道什么是mark-sweep-compact,对我来说,只记住了它是单线程的),图示和Serial类似; Parallel Old:
同理,多线程的GC collector; CMS:
全称“concurrent-mark-sweep”,它是最并发,暂停时间最低的collector,之所以称为concurrent,是因为它在执行GC任务的时候,GC thread是和application thread一起工作的,基本上不需要暂停application thread,如下图所示; 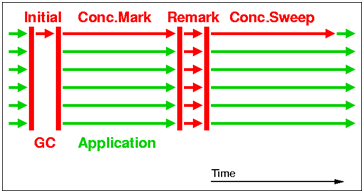
6种collector介绍完了。不过,在设定JVM参数的时候,很少有人去分别制定young generation和tenured generation的collector,而是提供了几套选择方案:
-XX:+UseSerialGC:
相当于”Serial” + “SerialOld”,这个方案直观上就应该是性能最差的,我的实验证明也确实如此;
-XX:+UseParallelGC:
相当于” Parallel Scavenge” + “SerialOld”,也就是说,在young generation中是多线程处理,但是在tenured generation中则是单线程;
-XX:+UseParallelOldGC:
相当于” Parallel Scavenge” + “ParallelOld”,都是多线程并行处理;
-XX:+UseConcMarkSweepGC:
相当于"ParNew" + "CMS" + "Serial Old",即在young generation中采用ParNew,多线程处理;在tenured generation中使用CMS,以求得到最低的暂停时间,但是,采用CMS有可能出现”Concurrent Mode Failure”(这个后面再说),如果出现了,就只能采用”SerialOld”模式了;
【3】中还提到了一个方案:UseParNewGC,不过我在其它地方很少看见有人用它,就不介绍了。
实验和结果 说了这么多,还是用实验验证一下吧。
被实验的系统可以看做是一个内存数据库,所有的数据和查询都是在内存中进行,测试用的workload即包含将数据写入到内存中,也包含各式各样的查询。这样一个系统和测试数据,在运行过程中,由于处理大量的查询,所以肯定会随时产生很多的短周期对象,所以young generation对应的Minor GC会比较频繁,同时,由于不断有新的数据写入到数据库,而这些数据都属于长周期对象,所以tenured generation的使用率是不断增长。 实验使用的是一台DELL的服务器,有48G内存,有2个CPU,各4个core,所以总共8个core。为了实验的方便,我只是用了大概16G内存给JVM使用。 SerialGC 先看第一张图: 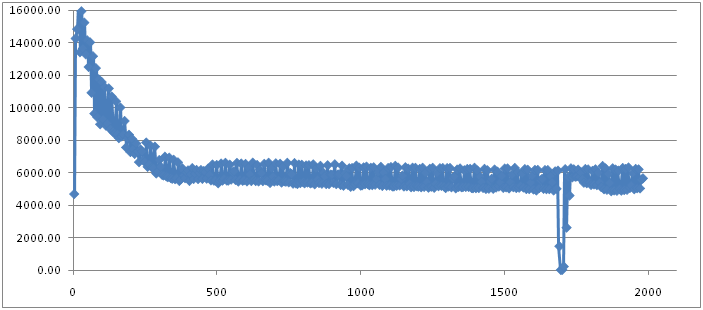
图中的采样点有些密集,截取其中的一小段放大如下: 
图的纵轴表示的是系统的throughput,单位是request/second。我设定的计算throughput的时间间隔是5秒,也就是说,图中的每一个点,都是一个5秒时间区间内系统throughput的平均值。
图的横轴表示的是时间维度。
后面几张图的设定和这个图是一样的。
这张图采用的是SerialGC,整个JVM的参数设置如下:
java -jar -Xms10g -Xmx15g -XX:+UseSerialGC-XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log Slaver.jar
其中,-XX:NewSize=6g -XX:MaxNewSize=6g表示的是将young generation的初始化size和最大size都设置成了6G,也就是说在整个系统运行过程中,young generation的size是不会变的。这是因为JVM会根据实际的运行情况动态的调节young generation和tenured generation的比例,而这样的设置能够避免这种动态的调整,便于观察实验结果。
-Xms10g -Xmx15g表示将JVM Heap的初始Size设置为10G,而它的最大Size设置为15G。相当于初始的时候tenured generation的大小约等于(10-6)G,而它可以增长为(15-6)G (只是近似计算,忽略了perm generation的size)。
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log这些参数,是将GC的细节和Heap的变化记录到gc.log中。
Slaver.jar是俺的程序....
对于后面的实验,这些参数都不会变动。唯一变动的就只是选择不同的Collector。 OK,回到实验结果图。
这张图有一个很有趣的现象是它的抖动非常大,几乎总是一个点高,紧挨着一个点就会低。这意味着系统的throughput在不断的震荡。这个现象的原因是实验过程中,Minor GC的发生频率基本上是7-9秒一次(通过log观察到的),而前面提到了我们计算throughput的时间区间是5秒,所以,基本上每隔一个时间区间就会发生一次Minor GC,而发生Minor GC的时间区间它的平均throughput就会降低。
为了证明这一点,我随意找了一段Minor GC的log:
900.692: [GC 900.692: [DefNew: 5334222K->300781K(5662336K), 0.8988610 secs] 7654628K->2641401K(9856640K), 0.8990190 secs] [Times: user=0.86 sys=0.03, real=0.89 secs]
解释一下这段log:
900.692表明这次GC发生在系统启动后的900.062秒这一时刻;
5334222K->300781K(5662336K)表明young generation在这次GC中从5334222K降低到了300781K,而young generation的size是5662336K(注意,这个值近似于我们之前设定的6G),这个过程花费了0.8988610秒;
7654628K->2641401K(9856640K) 表明这个JVM Heap从7654628K降低到了2641401K(这两个值之差应该和上面的那两个值之差几乎相等,因为这是Minor GC,所以整个Heap清理出的空间其实就是young generation清理出的空间);
user=0.86 sys=0.03, real=0.89 secs表明这次GC的user time是0.86,而real time是0.89秒 (不理解user/sys/real的见【4】)
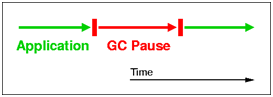
我们之前提到过,SerialGC是需要将整个application暂停的,所以,这次GC将整个application暂停了0.89秒,就是这个暂停导致了系统throughput的下降;
|